

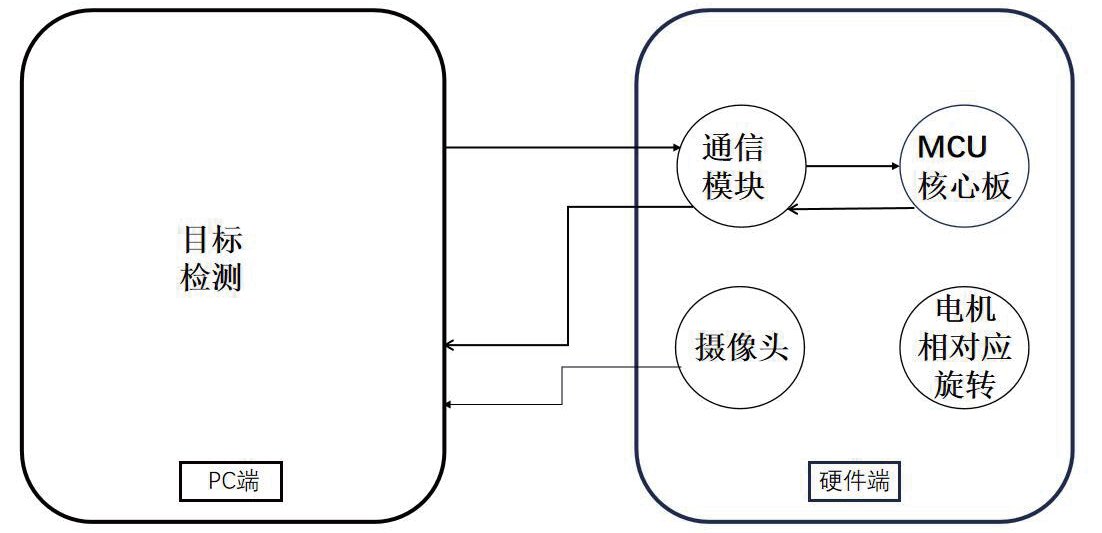
:本设计使用目标检测识别进行分类垃圾以代替传统的人工分类。本设计旨在用前沿的YOLOv3模型去实现准确的垃圾识别。设计中的模型利用Anaconda搭建环境变量,并在Pycharm软件上运行模型。YOLOv3模型实验所需的数据集来自华为云人工智能大赛提供的垃圾分类数据集,共有44种垃圾类别,图片数为1.9万张。经测试发现YOLOv3模型能够快速而又准确地识别出44种垃圾,随后通过蓝牙发出信号给STM32单片机部分,单片机通过控制舵机旋转后完成全自动化垃圾分类。
随着科技的快速发展,人们的生活水平得到了很大的改善,城市生活中的垃圾数量也随之飞速增长。近年来我国提出了全民垃圾分类的政策并在全国进行试点推广,为解决垃圾处理问题,各个城市相继出台了垃圾分类的地方标准,但实际执行起来依然有不小难度,用户的习惯和对垃圾分类知识了解的不足带来垃圾分类的现实困难,而设置专门的管理人员则会大量浪费人力资源。如果可以通过相关的设计实现自动分类的垃圾桶,将有助于大幅提升垃圾分类的准确率和效率。
深度学习技术的高速发展,它的功能也逐渐增强,尤其是在目标检测和图像识别等领域上发挥着重要作用。本文提出的基于深度学习的智能垃圾分类垃圾桶,该设计将人工智能与垃圾分类进行有机结合,提出了一种能够自动进行垃圾分类的垃圾桶的设计方案。方案的关键在于如何对目标准确而有效地识别,特别是应用性能较为优异的卷积模型作为目标检测的模型,对其在目标检测识别领域的应用具有十分关键以及重要的研究价值。
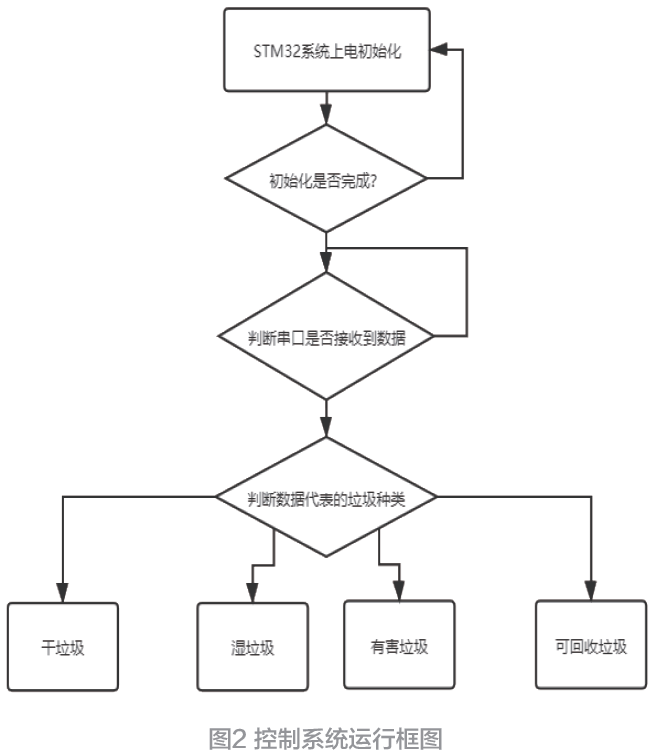
硬件部分的设计如图2 所示,STM32 上电后串口、定时器进行初始化。当STM32 收到电脑端发送的垃圾类型数据时,对收到的数据进行判断,用于区别出被识别垃圾的种类。当垃圾成功识别种类时,STM32 通过控制垃圾桶底部的垃圾旋转控制装置。旋转不同的角度使垃圾投放进不同分类的格子中。实现不同垃圾的分类效果。在实际执行中,系统将通过控制垃圾旋转装置旋转到一定角度来进行下方垃圾格子的选择,如干垃圾时旋转0° 、湿垃圾时旋转90° 、可回收垃圾旋转180° 、有害垃圾时旋转270° ,从而将垃圾投入下方系统定的格子中。
YOLOv3作为近期发布的模型,它对之前的算法既有保留又有改进。YOLOv3保留的结构如下所述。
(1)YOLOv1 中保留的结构是划分单元格来做检测,区别是划分的数量不一样。采用”leaky ReLU”作为激活函数,进行端到端地训练。一个loss function 即可搞定训练,因此只需关注输入端和输出端。
(2)YOLOv2 中保留的结构是用batch normalization(批量归一化,BN)作为正则化、加速收敛和避免过拟合的方法,把BN 层和leaky relu 层接到每一层卷积层之后。
DBL(Darknetconv2d_BN_Leaky):如图3 所示,是YOLOv3 的基本组件,包含了卷积+BN+Leaky relu。在YOLOv3 中,BN 和leaky relu 已经是和卷积层不可分离的部分( 最后一层卷积除外),共同构成了最小组件。其中BN 结构起到关键作用,它可减少训练计算量。计算公式如下:
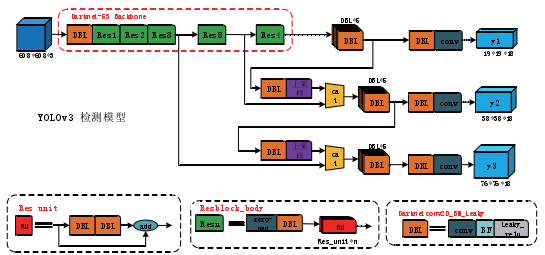
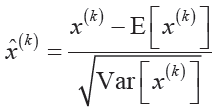
res_n:n代表数字,有res1,res2,…,res8 等等,表示这个res_block里含有多少个res_unit。这是YOLOv3的大组件,YOLOv3 开始借鉴了ResNet 的残差结构,使用这种结构可以让网络结构更深。残差结构相当于把图片中一些无用特征给过滤掉,提取出有用特征,从而增加本实验的识别精度。残差构如图4 所示。
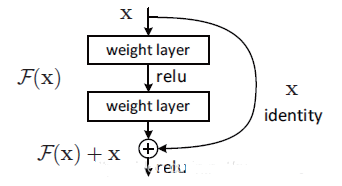
concat:张量拼接。将darknet 中间层和后面的某一层的上采样进行拼接。拼接的操作和残差层add 的操作是不一样的,拼接会扩充张量的维度,而add 只是直接相加不会导致张量维度的改变。
(1)当把YOLOv3 模型训练完成后,开始进行测试部分。训练出来的参数加载到测试部分时,可通过在电脑上的摄像头识别出不同种类垃圾。但是此垃圾识别过程不只是在电脑端完成的,它需要部署到硬件端。从图5 可看出实物中的大垃圾桶是装有可回收垃圾桶、有害垃圾桶、厨余垃圾桶、其他垃圾桶这四个小型垃圾桶的,系统是通过旋转小垃圾桶再把黑色平台上的垃圾倒入对应类别的特定垃圾桶中,而这个过程不可避免存在摄像头会拍到小垃圾桶中垃圾的可能,进而致误识别操作。

为解决此问题,本设计在垃圾被成功识别并发送了指令后用了一个中断操作,当识别完成后,识别的测试代码将停止运行,而硬件端的STM32 芯片将执行倒垃圾操作,倒完后又会反馈给识别代码端继续开启识别过程,从而避免了存在拍摄到垃圾桶内垃圾影响识别准确度的问题。
(2)测试代码中用的是开启摄像头识别模式,但是其本质还是把视频中的每帧图片逐一识别出来,这就涉及到识别灵敏度的操作问题。整个倒放垃圾的过程并不是一瞬间的,而是连续的。在每段识别过程中,可大致分为三种情形,一是垃圾完全没有出现在摄像头下,二是垃圾部分出现在摄像头下,三是垃圾全部出现在摄像头下。因为当垃圾只漏出部分时,识别所需要的特征是不清楚的,因此在这三种情况中第二部分最容易出现误识别操作,而如果按照每帧图片识别的话必定会出现垃圾还没放到黑色平台上,垃圾桶就开始运转的现象。为解决这个问题,本实验通过计算摄像头每秒多少帧和放垃圾这个动作大概需要多少时间,预先设置识别时间并改善识别灵敏度。经过多次的实践结果是,摄像头每秒30 帧,放垃圾的时间大约是2 秒左右,这个过程中识别到的图片大约为60 张,而60 张中一定会有误操作图片。本实验通过控制总的识别数量来控制最后发送给STM32 微的指令。实验结果表明,最佳值是在2秒内有20 张图片全部识别到同一物体时可发送对应指令给STM32 微。
智能垃圾分类垃圾桶系统设计包含硬件和软件两部分,在测试过程中,我们主要对软件部分进行了模型实验。将YOLOV3模型实验进行结果对比,在VGG(Visual Geometry Group)16 实验中用到了tensorflow、VGG16模型,并采用华为的垃圾识别数据集一共包括19 800张图44 个类别,先通过训练得出权重再分析实验结果对模型进行了一些微调,之后开始进行测试实验。在YOLOV3 模型中用的是torch、YOLOV3 模型,华为垃圾识别的数据集一共为19 800 张图44 个类别,先训练冻结部分为了加快训练,再使用解冻实验加强识别率和先验框,最后进行测试实验。硬件用到了STMF103、语音播放、舵机、蓝牙模块和摄像头。
构建完模型后把train 和val 的数据集划分为9 比1,epoch 一共为50,冻结和解冻的Batch_size 分别为8 和3,经过8 小时的训练。
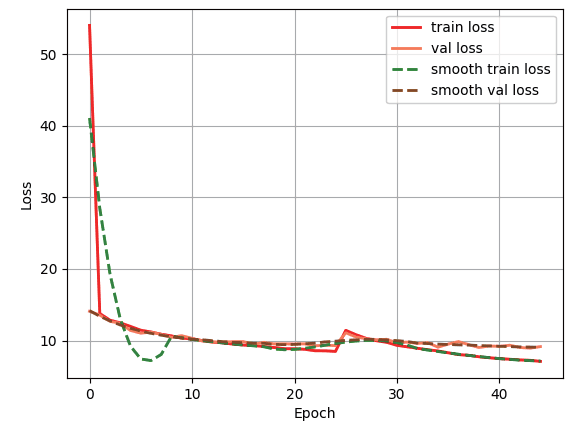
从图7 中可以看出训练集和验证集的loss 值都在同时下降,在实验中能够很好地排除背景干扰。
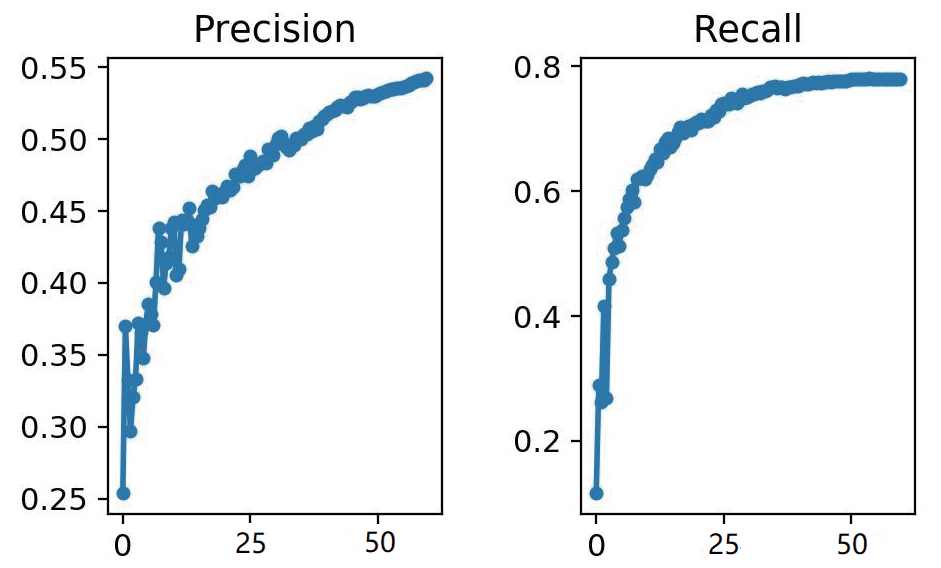
从YOLOv3 的实验结果可以得出,在训练轮数增加的同时模型没有出现过拟合状态,并且精确率与召回率也在不断增加,进而证明了模型优良。通过在实际应用上做出了具体改进,使得该垃圾识别系统更接近于应用到实际生活中。由于该系统的构造新颖,YOLOv3 模型的表现优异,打破了人们对传统垃圾桶的理解,使人们在生活中随处可见的垃圾箱变得更加人性化。采用该系统设计的智能垃圾分类垃圾桶更容易受大众接首,通过将垃圾在源头进行分类投放,并经过分类回收,使之重新变成资源,实现垃圾的二次甚至多次利用,符合国家号召的实现科学垃圾分类的既定目标。参考文献:


